- Title: QSO Selection Algorithm Using Time Variability and Machine Learning: Selection of 1,620 QSO Candidates from MACHO LMC Database
- Author: D. Kim, P. Protopapas, Y. Byun, C. Alcock, and R. Khardon
- Institution: CfA and Yonsei Unversity, South Korea

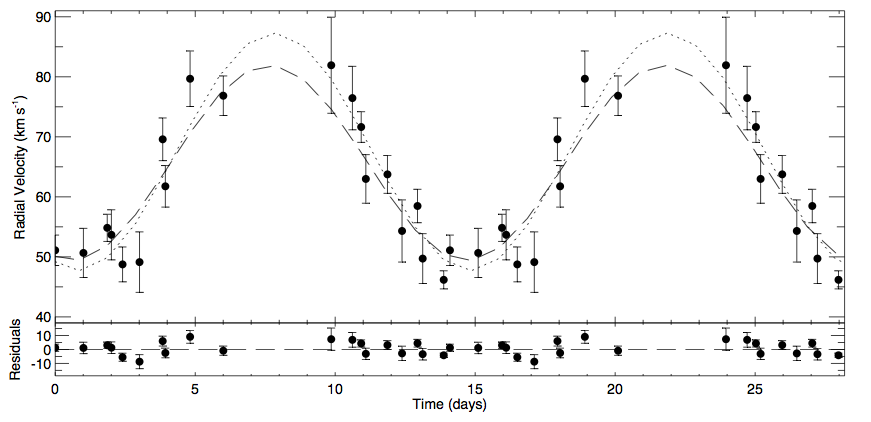
Figure 1 in the paper plots the autocorrelation function verse the time lag in days. The different patterns for RR Lyraes, microlensing events, and QSOs can help determine what an object might be.
With the advent of large photometric surveys, Astronomers must often work through massive amounts of data. In the 19th century Harvard Observatory employed women ‘computers’ to classify thousands of stellar spectra; today a graduate student might be dealing with millions of objects. To deal with these large numbers, some projects have the ingenious solution of involving people. For example, at Galaxy Zoo anyone with an internet connection can contribute to the field by classifying galaxies. Another solution is to train computers to do the job. This paper discusses such a computer algorithm to select candidate quasi-stellar objects (QSOs), the bright nuclei of galaxies that each house a supermassive black hole.
In the absence of spectroscopic data, the characteristic time variability of these objects is a useful identifier. The trick is to distinguish QSO variability from other objects such as variable stars (Cepheids, RR Lyraes, Be Stars, etc.), eclipsing binaries and microlensing events. The authors used 11 features to quantify the variability characteristics of lightcurves. Three of these are based on the autocorrelation function which is a measure of non-randomness in data. One application is to pick out a periodic signal, such as a sine function, in the presence of noise. For this analysis, the different patterns in the function can help determine what an object might be (see Figure 1). After defining the features to use in the selection process, the authors generated a model using a machine learning algorithm and data that has already been classified. This particular flavor of machine learning (there are many), is called a ‘Support Vector Machine’ (SVN). In essence, an SVN creates a model for determining whether an object falls in one of two categories based on the features you define and the examples or training set you provide.
The particular dataset discussed is from the MACHO survey of the Large Magellanic Cloud (LMC) designed to detect microlensing events of large, massive objects that contribute to the dark matter. The survey began collecting data in 1992 and this paper applied its trained model to 40 million lightcurves and ended up with 1,620 QSO candidates. The authors then looked at other catalogs to see if their objects had X-ray and Spitzer telescope counterparts, a sign of how powerful these sophisticated algorithms can be.

Trackbacks/Pingbacks