Title: emcee: The MCMC Hammer
Authors: Daniel Foreman-Mackey, David W. Hogg, Dustin Lang, Jonathan Goodman
First Author’s Institution: Center for Cosmology and Particle Physics, Department of Physics, New York University
Perhaps it would be best to let David Hogg introduce this paper:
…the fact that this is not a typical or normal kind of publication—for example, there is nowhere that it could appear in the peer-reviewed literature—is crazy: A great implementation of a good algorithm that enables lots of science is itself an extremely important contribution to science
What he’s talking about is a paper describing an implementation of a novel Markov chain Monte Carlo (MCMC) sampler called emcee that enables efficient Bayesian inference. If that sounds like gibberish to you, be sure to read the fantastic Astrobites post introducing Bayesian methods by Benjamin Nelson. You may also want to read another Astrobite about how astronomers (should) infer model parameters from data.

A contour plot of the Rosenbrock density "banana." The probabilty density is essentially zero outside of an extremely thin strip in 2D space. Figure from Goodman and Weare (2010).
To understand what makes emcee so great, the authors discuss a function that makes many MCMC samplers (like the venerable Metropolis-Hastings) break down, the Rosenbrock “banana” density:

To see how this function works, take a look at the contour plot at right. Essentially, the probability is of order unity when 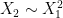
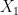
Let’s take a minute to put this in the context of a real-world problem. Suppose you had some data and a model that you want to fit to it that has the parameters 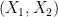
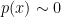
So what happens when you attack the banana with a simple Metropolis-Hastings sampler? Let’s say you start the sampler at 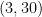
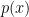
This is all well and good for finding your way to the banana, but the trouble begins once you get there. Once you reach the banana, your sampler has to walk a very narrow tightrope to reach the peak of the banana at 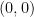
If you’re very clever, you may be able to solve problems of this type by coming up with a linear operator that transforms the

A stretch move for updating the position of X_k based on the position of another random walker, X_j. The light-gray walkers are other members of the team. Figure 2 from Goodman and Weare (2010).
Foreman-Mackey et al. have implemented such an affine-invariant sampler in emcee. Its major feature is that it doesn’t just send one walker out into the probability field, but instead an “ensemble” of walkers – a huge search team (preferably 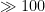
In the original paper describing this sampler (Goodman and Weare 2010), they find that the algorithm implemented in emcee would sample the banana > 10x faster than the Metropolis algorithm. They estimate this by taking the autocorrelation of the “trace,” the steps that the sampler makes as it wanders around the parameter space. This is essentially a measure of how often the sampler reaches new regions of the parameter space (takes independent samples) rather than getting stuck.
So you’re ready to use this code in your own projects? If you already have python and the pip installer, then getting emcee up and running could not be easier:
pip install emcee acor #as root
Now you can start playing with the quickstart examples on the emcee website. The code has already been used in several science projects – for example, to fit the parameters of a comet’s orbit and the stellar structure of the Milky Way disk.
The authors acknowledge that one limitation to this affine-invariant approach is that it requires that linear transformations be applied to the parameters (i.e that they can be stated as a vector). This doesn’t work for problems with certain constraints, such as integer-valued parameters. If you can figure out how to solve problems like this using emcee, you can contribute a patch to their GPLv2 source code. If you’re not so ambitious, you may want to check out other MCMC packages such as pymc, and consider archiving your code in the Astrophysics Source Code Library.



awesome tool, almost a game-changer for me.
matlab users might want to try my implementation here: http://www.mathworks.com/matlabcentral/fileexchange/49537-the-mcmc-hammer—affine-invariant-ensemble-mcmc-sampler